MongoDB C# Driver Review – Query Serialization
Posted: June 10, 2013 Filed under: Uncategorized | Tags: BSON, C#, code review, MongoDB Leave a commentWe know already how the BSON Serialization works. In an earlier article I paid more attention to the serialization of custom classes which is an important aspect for populating the database with data. Still, not only the data must be serialized. It should be also possible to formulate a search query, map-reduce or an aggregate command. There must also be a way to serialize this information to a BSON document and hand it over to a MongoDB server.
Let us take the search query as an example. User facing API is self-describing:
var query = Query.And(Query.GTE("x", 3), Query.LTE("x" , 10));
// { "x" : { "$gte" : 3, "$lte" : 10 } }
var cursor = collection.Find(query);
Using the Query class is not the only available option. Another one is the LINQ provider.
The And, GTE and LTE methods used in the code snipped are defined this way:
public static class Query
{
public static IMongoQuery And(params IMongoQuery[] queries) {...}
public static IMongoQuery GTE(string name, BsonValue value) {...}
public static IMongoQuery LTE(string name, BsonValue value) {...}
//...
}
The IMongoQuery is a marker interface. Since all builder-methods in the Query return it and the methods that build compound queries also accept it as a parameter, we can easily build query trees by combining several calls.
Implementation of the IMongoQuery is just a BsonDocument. It means that passing GTE and LTE over to the And query builds an BsonDocument consisting out of other documents. Binary and JSON serialization for BsonDocuments is provided out of the box (see BsonDocumentSerializer).
The BsonDocument is the DOM representing … ehm … BSON documents. BsonDocument consists of BsonElements which is a name value pair. The name is an arbitrary string and the value is a BsonValue which could be something serializable (or another BsonDocument).
When the query is ready, it goes into the MongoCollection and somewhere it must be serialized and sent over the pipe. But the MongoCollection accepts just a IMongoQuery and knows little about serialization.
The first option here is to use the BsonDocumentWrapper:
// somewhere in the MongoCollection
public virtual long Count(IMongoQuery query)
{
var command = new CommandDocument
{
{ "count", _name },
{ "query", BsonDocumentWrapper.Create(query), query != null }
};
var result = RunCommand(command);
return result.Response["n"].ToInt64();
}
Here the wrapper will be serialized, not direct the query. The wrapper is a IBsonSerializable and actually just serializes the underlying query using normal BsonSerializer.Serialize
// this class is a wrapper for an object that we intend to serialize as a BsonValue
// it is a subclass of BsonValue so that it may be used where a BsonValue is expected
// this class is mostly used by MongoCollection and MongoCursor when supporting generic query objects
public class BsonDocumentWrapper : BsonValue, IBsonSerializable
{
[Obsolete("Serialize was intended to be private and will become private in a future release.")]
public void Serialize(BsonWriter bsonWriter, Type nominalType, IBsonSerializationOptions options)
{
BsonDocumentWrapperSerializer.Instance.Serialize(bsonWriter, nominalType, this, options);
}
// ....
}
// somewhere in BsonDocumentWrapperSerializer.Serialize
BsonSerializer.Serialize(bsonWriter, wrapper.WrappedNominalType, wrapper.WrappedObject, null);
But not just this. The wrapper is also an BsonValue what means that it can be added as a node to a BsonDocument. Now we can use the query as a sub-element or sub-query. It is especially useful by running commands that consist of several queries. FindAndModify is a good example:
var command = new CommandDocument
{
{ "findAndModify", _name },
{ "query", BsonDocumentWrapper.Create(query), query != null },
{ "sort", BsonDocumentWrapper.Create(sortBy), sortBy != null },
{ "update", BsonDocumentWrapper.Create(update, true) },
{ "fields", BsonDocumentWrapper.Create(fields), fields != null },
{ "new", true, returnNew },
{ "upsert", true, upsert}
};
By the way, the code where a CommandDocument is built looks a bit like a JSON, what is kind of nice. This syntactic sugar is possible since the CommandDocument – same as any BsonDocument – is an IEnumerable and has specialized Add methods.
So, the BsonDocumentWrapper enables a query to be added to a BsonDocument as a BsonValue and used mostly to run commands.
The second trick to serialize a query is this extension method:
public static BsonDocument ToBsonDocument(
this object obj,
Type nominalType,
IBsonSerializationOptions options)
{
if (obj == null)
{
return null;
}
var bsonDocument = obj as BsonDocument;
if (bsonDocument != null)
{
return bsonDocument; // it's already a BsonDocument
}
var convertibleToBsonDocument = obj as IConvertibleToBsonDocument;
if (convertibleToBsonDocument != null)
{
return convertibleToBsonDocument.ToBsonDocument(); // use the provided ToBsonDocument method
}
// otherwise serialize into a new BsonDocument
var document = new BsonDocument();
using ( var writer = BsonWriter.Create(document))
{
BsonSerializer.Serialize(writer, nominalType, obj, options);
}
return document;
}
This is a small wrapper similar to ToJson and ToBson that with some casting produces an BsonDocument from an arbitrary object. The difference to the BsonDocumentWrapper is that the wrapper is a BsonValue, not a document, while query.ToBsonDocument() produces a standalone BsonDocument and can be also used e.g. to merge several documents together:
// MongoCollection.MapReduce
var command = new CommandDocument
{
{ "mapreduce", _name },
{ "map", map },
{ "reduce", reduce }
};
command.AddRange(options.ToBsonDocument());
And finally there is a third option to serialize the query. The query could be just handed over to Update, Delete or MongoQueryMessage and serialized there using BsonSerializer.Serialize in an existing BsonBuffer.
Conclusion
For query comprehension there is a Query class intended to be used as a public API backed up by a QueryBuilder. Everything produced by a Query is a IMongoQuery – marker interface with two implementations – QueryDocument, which is a BsonDocument and can be used overall where a BsonDocument can be used, and a QueryWrapper, which is just a IBsonSerializable. Additionally queries are supported by the BsonDocumentWrapper that can serve as a BsonValue.
For different operations there are several types of marker interfaces implementing same pattern. Just to name a few:
- IMongoUpdate (with Update/UpdateBuilder, UpdateDocument and UpdateWrapper)
- IMongoGroupBy (with GroupBy/GroupByBuilder, GroupByDocument and GroupByWrapper)
- IMongoFields (with Fields/FieldsBuilder, FieldsDocument and FieldsWrapper)
I do not really understand why there is a need in the *wrapper objects if there is always a *document, since the wrappers are just IBsonSerializable, same as the *documents. Just the BsonDocumentWrapper is notable for being a BsonValue.
Related articles:
- MongoDB C# Driver Review
- MongoDB C# Driver Review – Databases and Collections
- BSON Serialization with MongoDB C# Driver
MongoDB C# Driver Review – Databases and Collections
Posted: June 3, 2013 Filed under: Uncategorized | Tags: C#, code review, MongoDB 2 CommentsLast time I was looking into connection management in MongoDB. Now it is time to see how commands and queries work.
Looking again at this example:
var connectionString = "mongodb://localhost";
var client = new MongoClient(connectionString);
var server = client.GetServer();
var database = server.GetDatabase("test");
var collection = database.GetCollection("customers");
collection.Insert(new something{/* */});
var query = Query.And(
Query.EQ("FirstName", "Chanandler"),
Query.EQ("LastName", "Bong")
);
var res = collection.FindOne(query);
// and so on
Databases and Collections
First of all, what is going on here:
var database = server.GetDatabase("test");
var collection = database.GetCollection("customers");
What is inside the database and what is inside the collection?
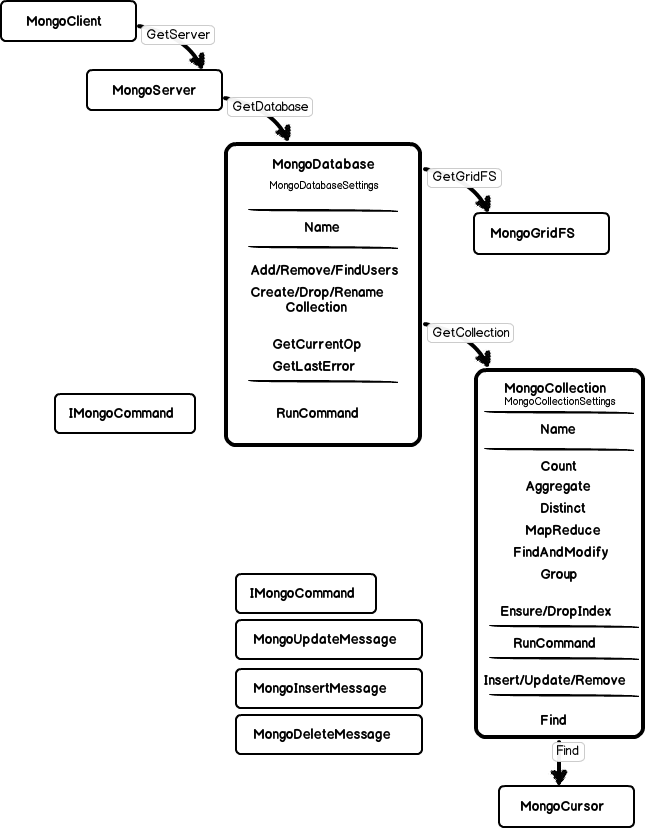
The database owns an instance of MongoDatabaseSettings that is mostly important for collections created out of this database. The first and foremost purpose of the Database seems to be a context for collections created out of it since the database name is a part of the fully qualified collection name.
Apart from this there is a number of friendly wrappers to manage users and collections. Like this one:
public virtual void AddUser(MongoUser user)
{
var users = GetCollection("system.users");
var document = users.FindOne(Query.EQ("user", user.Username));
if (document == null)
{
document = new BsonDocument("user", user.Username);
}
document["readOnly"] = user.IsReadOnly;
document["pwd"] = user.PasswordHash;
users.Save(document);
}
MongoDatabase.RunCommand is another handy option to start a command in context of the database that just forwards call to the database.$cmd collection.
Through the database we get also access to the MongoGridFS API (more on GridFS in a future post). MongoDatabase.GridFS looks somekind strange. Documentation says that this is the default instance for this database. But actually it is not exactly so:
///
/// Gets the default GridFS instance for this database. The default GridFS instance uses default GridFS
/// settings. See also GetGridFS if you need to use GridFS with custom settings.
///
public virtual MongoGridFS GridFS {
get { return new MongoGridFS(this); }
}
// hmm...
Assert.AreEqual(_database.GridFS, _database.GridFS);
But it does not seem to be a big problem. Anyway, this is just a GridFS-object with default settings. And there is a separate method to get it with custom options.
Turning to the MongoCollection. Through the settings it inherits from the database WriteConcern and ReadPreference. We see here the whole bunch of methods that start commands in the context of this collection – Count, Aggregate, Distinct, Geo searches etc. All of them build an appropriate BsonDocument and pass it over to the RunCommand, for example:
public virtual AggregateResult Aggregate(IEnumerable operations) {
var pipeline = new BsonArray();
foreach (var operation in operations) {
pipeline.Add(operation);
}
var aggregateCommand = new CommandDocument {
{ "aggregate", _name },
{ "pipeline", pipeline }
};
return RunCommandAs(aggregateCommand);
}
In MongoCollection we see at last how the RunCommand work – it actually uses FindOne to execute a CommandDocument.
Another important aspect in the MongoCollection – the CRUD operations. Insert, Update, Remove and Save acquire a connection from the server (MongoServer.AcquireConnection), build an appropriate BsonDocument and send it over the connection. All of these methods can use a user-specified WriteConcern or take the collection default value.
Before we turn to the Collection.Find – two words on index caching. As we saw earlier, the MongoServer contains something named IndexCache. Looking through the MongoCollection we now see how the index cache is used. MongoCollection can issue EnsureIndex or DropIndex but first it checks with the IndexCache if the index with this name has been created already by this process. So the IndexCache is a collection with index names created by this process. Not sure what happens if I create a new index and someone elsewhere deletes it. A new call to the EnsureIndex is not going to create it again since the index name is still cached.
The IndexCache can be resetted:
// MongoServer
///
/// Removes all entries in the index cache used by EnsureIndex. Call this method
/// when you know (or suspect) that a process other than this one may have dropped one or
/// more indexes.
///
public virtual void ResetIndexCache()
{
_indexCache.Reset();
}
But how am I going to know that the index was dropped by someone else? Not sure about that. Anyway, there is still MongoCollection.CreateIndex that does not use caching.
Cursors
MonogCursor and MongoCursorEnumerator is a IEnumerable/IEnumerator pair and deals with server-side cursors for particular queries.
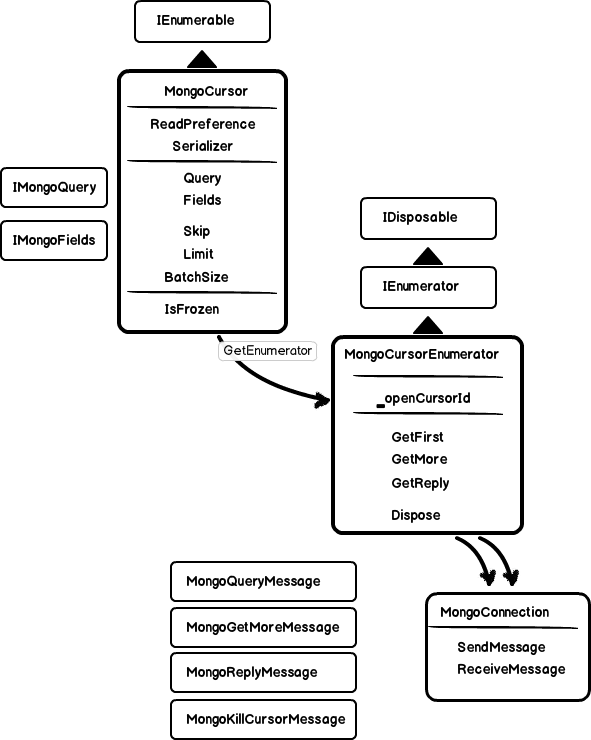
MongoCursor collects a number of settings that could be used later – like number of documents to return or batch size. Same as query flags. From MongoCollection it receives also an IMongoQuery and can modify it with additional options or set the fields that should be returned from the server.
var query = Query.And(
Query.EQ("FirstName", "Chanandler"),
Query.EQ("LastName", "Bong")
);
var cursor = collection.Find(query);
cursor.SetFields("FirstName")
.SetSortOrder("LastName")
.SetLimit(10);
But the real server cursor is first created during enumeration. At this point options of the MongoCursor cannot be modified any more (see IsFrozen) and a new instance of MongoCursorEnumerator is created. In the enumerator we see the real server cursor Id. The enumerator takes the query info from the MongoCursor and sends it over a connection to the server – in form of a MongoQueryMessage for a new cursor or MongoGetMoreMessage to continue iterate existing one.
Since a MongoDB server cursor is tied to a connection, the MongoCursorEnumerator must always use same MongoConnection instance to be able to access the opened cursor. It is assured in this method:
//MongoCursorEnumerator
private MongoConnection AcquireConnection()
{
if (_serverInstance == null)
{
// first time we need a connection let Server.AcquireConnection pick the server instance
var connection = _cursor.Server.AcquireConnection(_readPreference);
_serverInstance = connection.ServerInstance;
return connection;
}
else
{
// all subsequent requests for the same cursor must go to the same server instance
return _cursor.Server.AcquireConnection(_serverInstance);
}
}
GetFirst call acquires some arbitrary connection – a new one, or some existing, if there is any in the connection pool. GetMore always acquires connection using _serverInstance got after the GetFirst call.
The MongoCursorEnumerator is disposable and cleans server resources with MongoKillCursorMessage when disposed.
All the *Message classes – like MongoQueryMessage and MongoGetMoreMessage are in fact an implementation of the mongodb wire protocol. There are 6 message types to send data (insert, update, delete, query, getmore and kill cursor) and a single message to receive data. All of them have an corresponding opCode and can serialize information in the format of the mongo protocol.
Conclusion
This short insight has helped me to better understand how the driver work. There are enough other interesting parts of the project – like Authentication, GridFS or LINQ Provider. Should come to it later.
Related articles:
MongoDB C# Driver Review
Posted: May 24, 2013 Filed under: Uncategorized | Tags: C#, code review, MongoDB 4 CommentsMongoDB C# Driver consists of two parts:
- BSON Serialization support
- The Driver itself
We have already seen, how the most important components of BSON Serialization work. Now it is time to review the other part.
What we already know
From the documentation we know how to connect to the database, find and update data, set up indexes etc.:
var connectionString = "mongodb://localhost";
var client = new MongoClient(connectionString);
var server = client.GetServer();
var database = server.GetDatabase("test");
var collection = database.GetCollection("customers");
collection.Insert(new something{/* */});
var query = Query.And(
Query.EQ("FirstName", "Chanandler"),
Query.EQ("LastName", "Bong")
);
var res = collection.FindOne(query);
// and so on
It is pretty clear. Now it would be interesting to look underneath to understand how it actually works. Among others – why there is no something like open/close connection? How connections to different server configurations are managed (standalone, sharded, replica sets)? What is the way C# query does from Collection.Find to the network pipe? Answers to these and many other interesting questions we will find in the code.
The Client and the Server
Starting with first two lines:
var client = new MongoClient("mongodb://localhost");
var server = client.GetServer();
What is the client and what is the server – the code is rather confusing. According to JIRA the MongoClient was recently introduced to standardize the name of the root object across drivers and to support moving from the obsolete SafeMode to the new WriteConcern concept. And really – it is no more than that:
public class MongoClient
{
private readonly MongoClientSettings _settings;
public MongoClient(MongoClientSettings settings)
{
_settings = settings.FrozenCopy();
}
// a couple of convenience constructors
public MongoServer GetServer()
{
var serverSettings = MongoServerSettings.FromClientSettings(_settings);
return MongoServer.Create(serverSettings);
}
}
So, the whole difference between MongoClient and MongoServer is the usage of MongoClientSettings in place of MongoServerSettings. And what is the difference there?
- instead of obsolete SafeMode, the MongoClienSettings.WriteConcern is used with WriteConcern.Acknowledged as default
- instead of obsolete MongoServerSettings.SlaveOk, the MongoClientSettings.ReadPreference is used (SecondaryPreferred)
- same way AddressFamiliy is obsolete in favour of boolean MongoClientSettings.IPv6
Looking now at the MongoServer.
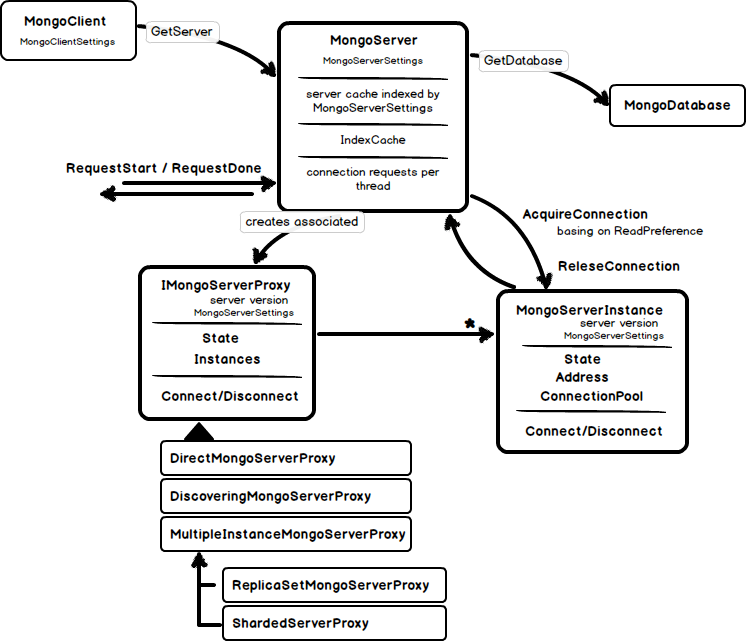
Several responsibilities could be identified here:
- Life cycle management for server proxies. We will see later what a server proxy is. For now it is interesting to know that a server proxy is created for every new MongoServer object and cached basing on current server settings. This behavior is going to be changed in the future
- access to a particular MongoDatabase
- connection management (at least partially)
- index cache
Apart from that the MongoServer contains whole bunch of methods that just delegate calls to underlying proxy or server instance.
I will come back to the connection management a bit later and cover MongoDatabase functionality in a separate post. For now let us have a look what are the server proxies good for. Apparently, there are separate implementation for each deployment configuration (standalone, replica set, sharded) that are created by the ServerProxyFactory depending on the configuration provided (and additional discovery proxy that automatically identifies server setup):
internal class MongoServerProxyFactory
{
public IMongoServerProxy Create(MongoServerSettings settings)
{
var connectionMode = settings.ConnectionMode;
if (settings.ConnectionMode == ConnectionMode.Automatic)
{
if (settings.ReplicaSetName != null)
{
connectionMode = ConnectionMode.ReplicaSet;
}
else if (settings.Servers.Count() == 1)
{
connectionMode = ConnectionMode.Direct;
}
}
switch (connectionMode)
{
case ConnectionMode.Direct:
return new DirectMongoServerProxy(settings);
case ConnectionMode.ReplicaSet:
return new ReplicaSetMongoServerProxy(settings);
case ConnectionMode.ShardRouter:
return new ShardedMongoServerProxy(settings);
default:
return new DiscoveringMongoServerProxy(settings);
}
}
It seems that the basic concept for the proxies is to locate an appropriate server instance to talk to basing on read preference. It has methods like Connect/Disconnect/Ping and can say current connection state. But in fact all connection requests are forwarded to underlying MongoServerInstances, who do real network communication job. The proxy just selects the right instance to talk to. For the DirectMongoServerProxy – which is a trivial case – it is just a single instance, while for Sharded- and ReplicaSet proxies several instances must be connected. Sharded proxy connects to one or many of mongos instances. And ReplicaSet proxy makes use of the ReadPreference to determine which proxy should be used for communication. DiscoveringMongoServerProxy is more interesting. It determines the server setup after all specified instances are connected (see also MongoServerInstance.InstanceType) and creates another proxy for this specific setup.
Connection Management
MongoServerInstance is created by proxies and represents a single mongo server. Three most interesting things you can get from a MongoServerInstance are:
- Connection state (Connected/Disconnected etc.)
- Server address
- General server information like version and server type – ReplicaSet, Sharded or Standalone.
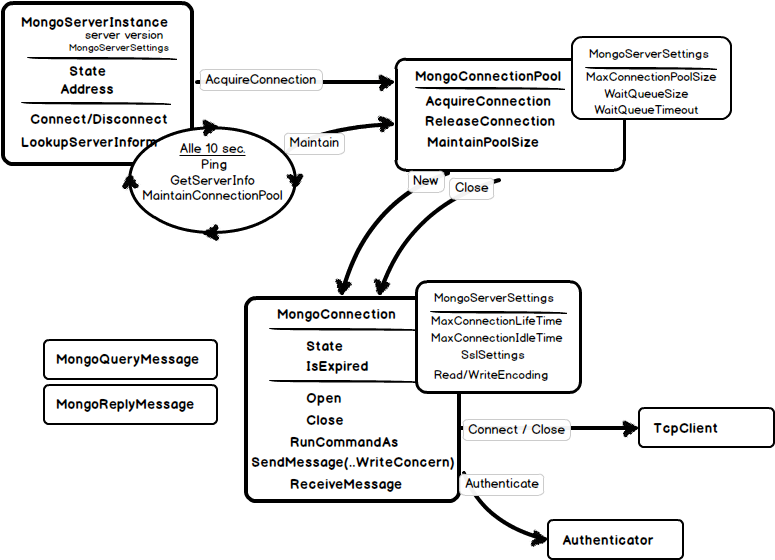
But probably even more important is the Connect method where a TCP connection to the physical server is requested to be opened. It is done indirectly since the connection could already exist and cached in the MongoConnectionPool. The Connection Pool is owned by the server instance and having such settings like pool size, waiting queue length and timeout can effectively decide if a new connection should be opened or existing should be used.
The only thing the MongoServerInstance should repeat time to time (every 10 sec) it to ask the connection pool to remove connections that are living too long (more than 30 min by default) or has not being used for more than 10 min. This way connections are opened and closed mostly indirectly – by connection pool. First connection will most probably be opened when the MongoServerInstance pings the mongo server and closed some time during pool maintenance.
What I really do not understand is that neither MongoConnection nor the MongoConnectionPool are disposable. Not sure why it is safe to close the process without closing TcpClient.
Turning to the MongoConnection itself, we see here direct TCP communication, including client certificate handling and authentication (Kerberos and MongoDB-own challenge-responce protocol MONGODB-CR are supported). And – probably the heart of client/server communication – the SendMessage method. Actual BsonDocuments are serialized here to the pipe and – depending on write concern – the server answer is read using ReceiveMessage. The handling of WriteConcern and GetLastServer error should be definitely noted here.
Another interesting part of connection management belongs to the MongoServer:
public class MongoServer
{
internal MongoConnection AcquireConnection(ReadPreference readPreference) { /* ... */ }
internal MongoConnection AcquireConnection(MongoServerInstance serverInstance) { /* ... */ }
internal void ReleaseConnection(MongoConnection connection) { /* ... */ }
///
/// Lets the server know that this thread is about to begin a series of related operations that must all occur
/// on the same connection. The return value of this method implements IDisposable and can be placed in a
/// using statement (in which case RequestDone will be called automatically when leaving the using statement).
///
public virtual IDisposable RequestStart(MongoDatabase initialDatabase) { /* ... */ }
public virtual void RequestDone() { /* ... */ }
}
private class RequestStartResult : IDisposable
{
private MongoServer _server;
public RequestStartResult(MongoServer server)
{
_server = server;
}
public void Dispose()
{
_server.RequestDone();
}
}
AcquireConnection and ReleaseConnection is an internal API that is used throughout the driver to run a command or query and boils down to the ConnectionPool.Acquire/ReleaseConnection. This way all other infrastructure classes – like MongoDatabase, MongoCollection or MongoCursor – must have a reference to the MongoServer. At least to be able to start a command. It will certainly not simplify MongoServer removal in the future.
RequestStart and RequestDone are no more than friendly version of Acquire/ReleaseConnection with some necessary handling of nesting calls and thread affinity.
Conclusion
I hope that I covered most important connection management parts. I also hope that I could get at least partial feeling of the code and its design implications.
Next time – more about MongoDatabase, MongoCollection and probably a bit about communication protocol.
Related articles:
- C# Driver Tutorial
- MongoDB Manual: Default Write Concern Change
- Authenticate to MongoDB with the C# Driver
- BSON Serialization with MongoDB C# Driver
BSON Serialization with MongoDB C# Driver
Posted: February 26, 2013 Filed under: Uncategorized | Tags: BSON, C#, code review, MongoDB 1 CommentMongoDB C# Driver consists of two parts:
- BSON Serialization support
- The Driver itself
In this post we will have a look at the most important components of BSON Serialization and how it works under the cover. So let’s pull the Git repository and drill into the code.
High-Level API: ToJson and ToBson
Going top-down: the high-level serialization API are two handy extension methods: ToJson and ToBson. They can be used on an arbitrary object and hide complexity of underlying machinery:
There is an extensive set of unit tests for the C# Driver. Most of my code snippets are based on that tests.
[Test]
public void TestToJson()
{
var c = new C { N = 1, Id = ObjectId.Empty };
var json = c.ToJson();
Assert.That(json, Is.EqualTo(
"{ \"N\" : 1, \"_id\" : ObjectId(\"000000000000000000000000\") }"));
}
[Test]
public void TestToBson()
{
var c = new C { N = 1, Id = ObjectId.Empty };
var bson = c.ToBson();
var expected = new byte[] { 29, 0, 0, 0, 16, 78, 0, 1, 0, 0, 0, 7, 95, 105, 100, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
Assert.IsTrue(expected.SequenceEqual(bson));
}
Looking inside implementation we’ll immediately see, that the these are just thin wrappers for couple of other classes and call to BsonSerializer.Serialize as the central point:
// ToBson
using (var buffer = new BsonBuffer())
{
using (var bsonWriter = BsonWriter.Create(buffer, settings))
{
BsonSerializer.Serialize(bsonWriter, nominalType, obj, options);
}
return buffer.ToByteArray();
}
// ToJson
using (var stringWriter = new StringWriter())
{
using (var bsonWriter = BsonWriter.Create(stringWriter, settings))
{
BsonSerializer.Serialize(bsonWriter, nominalType, obj, options);
}
return stringWriter.ToString();
}
We’ll see later what is the purpose of BsonWriter.
For deserialization there are no extension methods, so one need directly grab the BsonSerializer:
// BSON var c = BsonSerializer.Deserialize(bsonBytes); Assert.AreEqual(1, c.N); // Json var c = BsonSerializer.Deserialize(jsonString); Assert.AreEqual(1, c.N);
This is pretty much it – couple of straightforward functions that could cover 80% of use cases. For other 20% we should understand how it works underneath.
There is also an API for (de)serialization in form of DOM aka BsonDocument. Although BsonDocument is something completely different comparing to raw BSON byte stream, serialization is implemented using same design concepts – dependency injection in action.
Middle-Level: BsonReader, BsonWriter and BsonSerializer
Stepping one level down, we are getting to BsonReader and BsonWriter. These are actually class families with specific implementation for three related formats: BSON, Json and BsonDocument. Surfing through the code, it is not difficult to identify their responsibility: (de)serialize particular elements seeking over incoming/outgoing buffer – much like System.IO.BinaryReader or System.Xml.XmlReader. It means that for example BsonBinaryReader/Writer pair implements the BSON specification for particular elements and JsonReader/Writer do same for Json, including Mongo-related extensions like ObjectIds and $-notation for field names.
[Test]
public void TestRegularExpressionStrict()
{
var json = "{ \"$regex\" : \"pattern\", \"$options\" : \"imxs\" }";
using (var bsonReader = BsonReader.Create(json))
{
Assert.AreEqual(BsonType.RegularExpression, bsonReader.ReadBsonType());
var regex = bsonReader.ReadRegularExpression();
Assert.AreEqual("pattern", regex.Pattern);
Assert.AreEqual("imxs", regex.Options);
Assert.AreEqual(BsonReaderState.Done, _bsonReader.State);
}
var settings = new JsonWriterSettings { OutputMode = JsonOutputMode.Strict };
Assert.AreEqual(json, BsonSerializer.Deserialize(new StringReader(json)).ToJson(settings));
}
Responsibility of BsonSerializer in this context is to orchestrate individual calls to the readers and writers during serialization and compose result.
All in all the whole high-level process could be drawn this way:

Low-Level: Serializers and Conventions
Stepping down once again to see individual components under BsonSerializer:

BsonSerializer contains collection of serialization providers that can be used to look up particular serializer. An Serializer is something like this:

It is hardly to overlook the ambiguity between BsonSerializer and IBsonSerializer. Nevertheless the classes serve very different purposes. The first one is the static class and the central point for the whole serialization logic, while the second one contains numerous particular implementation for the whole bunch of types and normally should not be used directly.
From this definition of IBsonSerializer we can identify its purpose – to create an object of specified type using particular BsonReader and vice versa. So the control flow is as follows:
- BsonSerializer is called to (de)serialize specific type using particular reader or writer
- It asks then an serialization provider (registry of particular serializers) if there is a serializer registered for the requested type
- If there is one, the serializer triggers the actual low-level process, orchestrate calls to readers and writers
There are two predefined serialization providers – BsonDefaultSerializationProvider and BsonClassMapSerializationProvider. The Default provider is always used as the first one and delivers serializers for most of .NET native types and specialized BSON types (like ObjectId or JavaScript). If there is no predefined serializer for the requested type, then the ClassMap provider is used to engage the BsonClassMapSerializer. This one is a very powerful facility to handle user-defined types. The most important aspect here is the configuration of object-to-BSON mappings.
The mapping is handled by the BsonClassMap that contains all metadata for the requested type like serializable member names and their order, id field and id generation strategy, discriminator fields for polymorphic types and lots more. It works out of the box with reasonable behavior, but is also highly customizable:
BsonClassMap.RegisterClassMap(cm =>
{
cm.MapIdProperty(e => e.EmployeeId);
cm.MapProperty(e => e.FirstName).SetElementName("fn");
cm.MapProperty(e => e.LastName).SetElementName("ln");
cm.MapProperty(e => e.DateOfBirth).SetElementName("dob").SetSerializer(new DateOfBirthSerializer());
cm.MapProperty(e => e.Age).SetElementName("age");
});
Nice to see that implementation of all customization concepts is not gathered in single place, but distributed over particular components, aka conventions. Every convention is responsible for some mapping aspect and could be applied to the BsonClassMap to update current configuration. (For example the MemberNameElementNameConvention could be applied to a MemberMap of BsonClassMap to set the corresponding BSON element name which surely should be same as the class member name, if not overridden by AttributeConvention using BsonElementAttribute.)
class TestClass
{
[BsonElement("fn")]
public string FirstName;
}
[Test]
public void TestOptsInMembers()
{
var convention = AttributeConventionPack.Instance;
var classMap = new BsonClassMap();
new ConventionRunner(convention).Apply(classMap);
Assert.AreEqual(1, classMap.DeclaredMemberMaps.Count());
Assert.AreEqual("fn", classMap.GetMemberMap("FirstName").ElementName);
}
Conclusion
The whole class structure is very powerful. You can do pretty everything you want by plugging into it at an appropriate place:
- Manipulate serialization process using IBsonSerializationOptions
- Fine tune BSON structure though manual configuration of BsonClassMap
- Implement and register own conventions for user defined types
- Implement a serializer for your very special types and register it with own serialization provider
All in all it is very nice to see good separation of concerns in action – with few exceptions.
Further Reading:
